
Nociones básicas de R
Introducción
En este apunte se pretende desarrollar los recursos que ofrece el software estadístico R para el tratamiento y análisis de datos en el ámbito de las ciencias sociales. Para ello se trabajará con las bases de datos del Programa de Investigación sobre la Sociedad Argentina Contemporanea (PISAC) y se irá desarrollando las herramientas y potencialidades del software en función a estos datos. Comenzaremos en un primer momento con la instalación del software y luego pasaremos a la utilización del mismo.
Instalación de R y RStudio
Primeramente se requiere la instalación de R, para ello diríjase al sitio web oficial luego en el margen izquierdo seleccionar Download > CRAN > elegir el enlace para Argentina > seleccionar el sistema operativo > clic en “install for the first time” > y por ultimo clic en Download R. Comenzará la descarga, luego seguir los pasos de la instalación. Posteriormente, instalar R Studio desde el sitio web y dirigirse donde dice Download R Studio > en la sección FREE hacer clic en Download now > elegir el sistema operativo. Comenzará la descarga, luego seguir los pasos de la instalación.
¿Qué es R Studio IDE?
R Studio - Entorno de Desarrollo Integrado (IDE) es una interfaz de trabajo que fue desarrollada por la companía R Studio, la cuál nos permite utilizar todas las herramientas y potencialidades que tiene el software R en un entorno de trabajo más cómodo y productivo. Puede ver más características aquí. Una vez instalado el programa, al ejecutarlo se puede apreciar que en su interfaz presenta cuatro ventanas diferentes de visualización; las mismas son el editor de código fuente (script) y visor de datos, Espacio de trabajo e historial, Consola y Fichero, visualizaciones, ayuda y paquetes, tal como se puede ver en la Imagen 1 a continuación.
Imagen 1 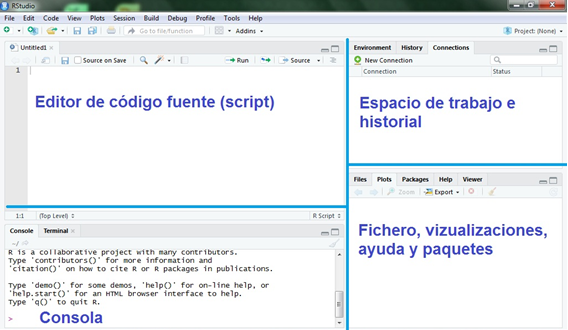
Editor de código fuente (script): es el espacio en donde se generan los códigos y las funciones.
Consola: en esta ventana se observan los resultados de las funciones y códigos que se ejecutan en el editor de código fuente (script).
Espacio de trabajo e historial: aquí se almacenan todos los objetos que se crean.
Fichero, visualizaciones, ayuda y paquetes: se observan aquí el fichero o directorio, los gráficos que se generan, se instalan paquetes y se ven los paquetes ya instalados, también se encuentra una sección de ayuda.
Objetos en R
Existen 5 tipos de datos básicos en R, los cuales són Vector, Factor, Matrix, Dataframe y Lista. De estos solamente nos interesa para el análisis de datos en ciencias sociales los siguientes:
• Vector: es un objeto que permite almacenar datos de tipo numérico y caracter.
• Factor: este tipo de objeto se utiliza para almacenar datos de tipo categórico, los mismos pueden ser nominales u ordinales.
• Dataframe: es el tipo de objeto que almacena los datos en forma de matriz de datos, es decir con filas y columnas, donde cada fila representa a una unidad de análisis y cada columna representa a una variable
Aclaración: Una vez estando en R Studio es importante que primeramente se defina el fichero de trabajo o directorio, ya que es allí donde se guardarán todos los archivos que se necesitarán y crearán de ahora en adelante. Entonces, en la parte superior derecha haciendo clic en Project > New Project > New Directory > New Project y seleccionando la ruta definimos el directorio.
Caracteres especiales
Tabla 1 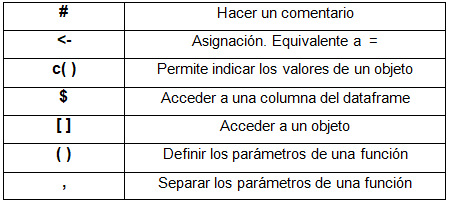
Aclaración: Se ejecutan o “corren” los comandos y funciones combinando las teclas Ctrl + Enter en Windows y si utiliza Mac debe combinar Cmd + Enter Veamos algunos ejemplos simples sobre estos caracteres. Ubicados en la ventana de script, escribimos lo siguiente:
# Se utiliza el símbolo <- para asignarle algún valor al objeto
A <- 6
A## [1] 6# A su vez es posible crear otro objeto a partir del anterior
B <- A + 20
B## [1] 26# También con estos objetos se puede realizar operaciones aritméticas
A + B## [1] 32C <- A + B
C## [1] 32D <- B / A * C
D## [1] 138.6667Operadores lógicos
Tabla 2 
Ejemplos usando operadores lógicos:
# Comparación lógica
A > B## [1] FALSEA < B## [1] TRUEB == A## [1] FALSEB != A## [1] TRUEA >= B## [1] FALSEB <= A## [1] FALSEContinuemos creando objetos a modo de variables:
# Crear un vector numérico
Edad <- c(23, 50, 18, 30, 45, 34, 60)
Edad## [1] 23 50 18 30 45 34 60Se puede ver que se trata del vector “Edad” con siete valores numéricos.
# Crear un factor
#Para la variable Asistio al curso con valores 1 = Si; 2 = No
Asist_curso <- c(1, 2, 2, 1, 1, 2, 1)
# Indicamos que se trata de un objeto de tipo factor con categorías Si y No
Asist_curso <- factor(Asist_curso, levels = c(1, 2), labels = c("Si", "No"))
Asist_curso## [1] Si No No Si Si No Si
## Levels: Si NoSe puede ver que se trata del factor “Asist_curso” con dos valores categóricos nominales.
Suponiendo que se desea crear un factor ordinal para la variable Nivel educativo, con valores: 1 = Bajo, 2 = Medio, 3 = Alto, el procedimiento es el siguiente:
# Crear un vector numérico que registre los valores:
Nivel_ed <- c(1, 3, 3, 2, 1, 1, 2)
# Convertir el vector en un factor e indicar los valores Bajo, Medio y Alto
Nivel_ed <- factor(Nivel_ed, levels = c(1, 2, 3), labels = c("Bajo", "Medio", "Alto"))
# Indicar que se trata de un factor ordinal:
Nivel_ed <- ordered(Nivel_ed)
Nivel_ed## [1] Bajo Alto Alto Medio Bajo Bajo Medio
## Levels: Bajo < Medio < AltoSe puede ver que se trata de un factor con valores ordinales Bajo, Medio y Alto.
Ahora bien, para crear un dataframe (matriz de datos) añadiendo estos objetos (variables) que se han creado anteriormente, los pasos a seguir son los siguientes:
# Crear el dataframe "datos" con la función data.frame()
datos <- data.frame(Edad, Asist_curso, Nivel_ed)
datos## Edad Asist_curso Nivel_ed
## 1 23 Si Bajo
## 2 50 No Alto
## 3 18 No Alto
## 4 30 Si Medio
## 5 45 Si Bajo
## 6 34 No Bajo
## 7 60 Si MedioAclaración: Debe tener en cuenta que R sí hace diferencia entre caracteres. Por lo tanto, es necesario prestar mucha atención en el caso que use letras mayúsculas o minúsculas.
A esta altura la interfaz de R Studio debería tener el siguiente aspecto:
Imagen 2 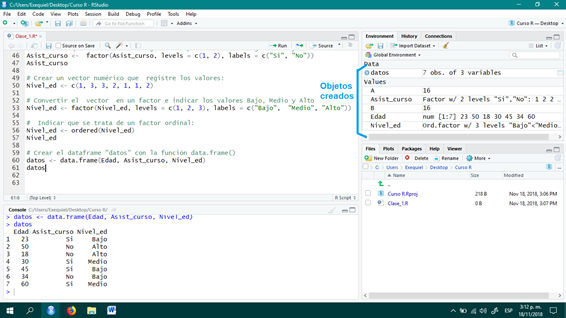
Paquetes
Los paquetes en R nos permiten incorporar herramientas adicionales y ampliar sus funcionalidades. R trae incorporado algunos paquetes básicos, pero podemos instalar otros de distintas maneras. Desde la consola a través del comando install.packages(), desde la ventana de visualización de paquetes, en la pestaña “packages” o bien desde la barra de menú en la pestaña “Tools” > Install packages. Procedamos a instalar el paquete Foreign, que se utilizará más adelante para importar bases de datos mediante la función install.packages().
Aclaración: Basta con realizar la instalación solo una vez para que los paquetes queden guardados definitivamente, pero es necesario ejecutarlos cada vez que se inicia una nueva sesión en R mediante la función library().
install.packages("foreign")Importar bases de datos
En este curso vamos a trabajar con las bases de datos del Programa de Investigación Sobre la Sociedad Argentina Contemporánea (PISAC) que están disponibles para la descarga aquí. Las bases se encuentran disponibles en formatos .csv y .sav para lo que respecta a los hogares y las personas, de las cuales solo vamos a utilizar la que es en formato .sav. Antes de importar las bases de datos primeramente es necesario que las mismas estén guardadas en la carpeta del directorio de trabajo que definimos al comienzo cuando guardamos el proyecto. Entonces, con las bases ya guardadas en dicha carpeta vamos a comenzar importando las bases de los hogares y las personas.
# Primero abrimos la librería del paquete foreign
library(foreign)
# Importar base
hogares <- read.spss("ENES_Hogares_version_final.sav", to.data.frame = TRUE)
personas <- read.spss("ENES_Personas_version_final.sav", to.data.frame = TRUE)Hemos importado las bases de datos, ahora pasaríamos a explorarlas para ver en qué estado se encuentran los datos que contienen. Hay algunas funciones básicas que se utilizan para realizar esta operación:
Tabla 3 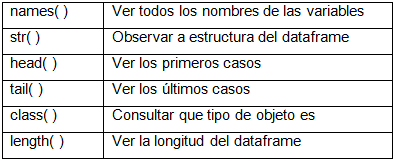
Veamos algunos ejemplos:
class(hogares)## [1] "data.frame"length(personas)## [1] 157names(personas)## [1] "nocues" "nhog" "miembro" "f_calib3" "region"
## [6] "aglo" "t_aglo" "estrato_U" "cod_U" "v108"
## [11] "v109" "v110" "v111" "v112" "v113"
## [16] "v114" "v115" "v116" "c_hogar" "t_hogar"
## [21] "v117" "v118a" "v118b" "v118c" "v119"
## [26] "v120" "v121" "v122" "v123" "v124"
## [31] "v125" "nivel_ed" "v126" "v127" "v128"
## [36] "v129" "v130" "v131" "v132" "v133"
## [41] "v134a" "v134b" "v135" "v136" "v137"
## [46] "v138" "v139" "v140" "v141" "v142"
## [51] "v143" "v144" "v145" "v146" "v147a"
## [56] "v147b" "v147c" "v148" "v149a" "v149b_pcia"
## [61] "v150" "v150b_pais" "v151" "v152a" "v152b_lugar"
## [66] "v153" "v154" "v155" "v156" "v157"
## [71] "v158" "v159" "v160" "v161" "v162"
## [76] "v163" "v164" "v165" "v166" "v167"
## [81] "v168" "v169" "v170" "v171" "v172"
## [86] "v173" "v174" "v175" "v176" "v177"
## [91] "v178" "estado" "v179" "v180" "v181"
## [96] "v186" "v187" "v182caes" "v183ciuo" "v183cno"
## [101] "v188" "v189" "v190" "v191" "v192"
## [106] "v193" "v194" "v195" "v196" "v197"
## [111] "v198" "v199" "cat_ocup" "egp11" "CSO"
## [116] "v200" "v201a" "v201b" "v201c" "v201d"
## [121] "v202" "v203a" "v203b" "v203c" "v203d"
## [126] "v203e" "v203f" "v204" "v205" "v206a"
## [131] "v206b" "v207" "v208" "v209" "v210a"
## [136] "v210b" "v211" "v212" "v213a" "v213b"
## [141] "v213bi" "v214a" "v214b" "v214bi" "ITLi"
## [146] "ITLi_d" "v215a" "v215b" "v215bi" "v216a"
## [151] "v216b" "v216bi" "v217a" "v217b" "v217bi"
## [156] "ITI" "ITI_d"Puede continuar ejecutando cada una de estas funciones siguiendo la estructura funcion(nombre.del.dataframe).
Seleccionar una variable
Si queremos observar alguna variable en particular de la base de datos, debemos utilizar el símbolo $. Por ejemplo, para seleccionar la variable Clase social de pertenencia del Principal Sostén del Hogar (el nombre de esta variable es v260a) de la base de hogares:
class(hogares$v260a)## [1] "factor"Otras funciones para explorar variables:
Tabla 4 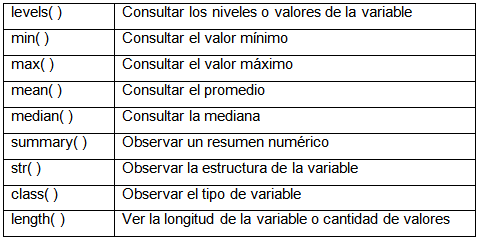
Algunos ejemplos:
# Consultar los valores de la variable v260a
levels(hogares$v260a)## [1] "Clase baja" "Clase obrera" "Clase media baja"
## [4] "Clase media" "Clase media alta" "Clase alta"
## [7] "NS/NR"# Ver la cantidad de valores que tiene la variable v260a
length(hogares$v260a)## [1] 8265# Para la variable v235i - Ingreso Total del Hogar el mes pasado (imputado)
# Promedio de v235i
mean(hogares$v235i)## [1] 12928.3# Resumen numérico de v235i
summary(hogares$v235i)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 200 6056 9973 12928 16000 128371Referencias
Este post está basado en los siguientes materiales:
WICKHAM H., GROLEMUND G. “R for Data Science” (2017). Recuperado de: https://r4ds.had.co.nz/
MENDIZABAL S. “Taller de Introducción a R” (2017). Recuperado de: https://songeo.github.io/introduccion-r-bookdown/
WEKSLER G., KOZLOWSKI D., SHOKIDA N., “Curso de R para procesamiento de datos de la Encuesta Permanente de Hogares” (2018). Recuperado de: https://diegokoz.github.io/Curso_R_EPH_clases/
